Semantic Dependency Parsing
(sortof)
Phillip Alday
Philipps-Universität Marburg phillip.alday at staff.uni-marburg.de

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
Prerequisites
Suddenly you find out that while most computer scientists don’t know much linguistics, and most linguists don’t know much about computer science, computational linguists can open a can of whoop-ass on you in either field.
Source: SpecGram
Brains and Waves
Electrophysiology
- EEG measures summed electric potentials of nerve cells perpendicular to scalp
- source localization not possible without additional (biological) assumptions
- extremely high temporal resolution (ms) but poor spatial resolution (many cm3, probabalistic)
Raw EEG to ERP

Functional Neuroanatomy
- fMRI measures BOLD (blood oxygen level dependent) signal
- oxygenated blood flow thought to correlate with neural activity
- high spatial resolution (< cm3), but poor temporal resolution (5s)
- often reduced to comparing pretty pictures, despite the incredibly complex nature of the data
Pretty Pictures
(and sometimes bad science)
Modelling Cognition
Issues in Measurement
Measuring “Effort”
- neurophysiologically not obvious
- cancellation effects
- weak correlations of indirect, partial measures
- weak correlation with perception of effort (often tied to notions of “good” useage)
- reaction time a problematic measure due to concurrency issues
Measuring “Accuracy”
- no direct measure beyond self-reporting
- very difficult to pose a good question
“Natural” Language
- environmental effects
- task effects
- types of sentences used
Behavior and Blackboxes
- currently no way to completely measure or model neural “state”
- measure “power consumption” (EEG) and “heat” (fMRI)
- individual variation
- genetics
- experience
But We Don’t Even Have a Blackbox
- input for speech perception and processing
- output for speech production
- but never input and output simultaneously!
and never internal representation, which is the very thing we want to model
maybe we should just call it quits…
but then again bootstrapping is always hard
What are we modelling?
- computational processes (algorithms)?
- neural implementation (hardware)?
Previous Work
- focus on algorithms (psycholinguistics):
- constituency parsing (traditional grammatical theories)
- bounds on hashing and caching, evaluation strategy (memory constraints)
- focus on hardware architecture (neurolinguistics)
- division of processing activities (localization, functional connectivity)
- sufficient and necessary conditions (aphasia studies)
General Trends
- qualitative explanations of quantitative methods
- highly noisy data + poor specifity + traditional significance testing
- partial orderings
- blinded by origins:
- linguists: syntax über alles!
- psychologists: our memories define us
- neurologists: from anatomy to physiology to cognition
- computer scientists: (sub)symbolic,(non)deterministisc, bounded?
extended Argument Dependency Model
Bornkessel-Schlesewsky & Schlesewsky (2006,2008,2009,…)
Assumptions and Observations
Language is processed incrementally
The same basic cognitive mechanisms are used for all languages.
(First) Language acquisition is largely automatic, instinctual and unsuperivised.
(Morpho)Syntax isn’t enough.
Well-formed, sensical, unambiguous
 ### But still dispreferred!
### But still dispreferred! 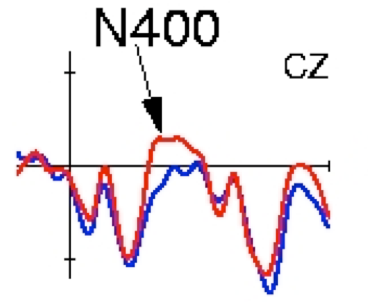
Source
Ambiguities
Die Gabel leckte die Kuh.
The fork licked the cow.
- many sentences are ambiguous “syntactically”
- yet we usually only get one interpretation
- but even humans aren’t sure of the correct interpretation for some sentences:
The daughter of the woman who saw her father die…
Non-Ambiguities
- traditional subjects break down outside of traditional languages
- ergativity
- topic prominence
- quirky case
- problems even in traditional languages:
- passives without a syntactic subject: Mir wurde gesagt, dass nach meiner Abreise noch stundenlang gefeiert wurde.
- semantically void subjects
- differences with object-experiencer verbs
Interestingly, (syntactic) dependency grammars seem to have somewhat fewer difficulties with typological variation…..
Actor
- roughly the syntax-semantics interface element corresponding to the mapping between “(proto)-agent” and “subject”
- prototype for a causative agent
- fits well with language processing being part of a more general cognitive framework
- can be viewed as “root” dependency
- no effect without cause
- no undergoer (~patient) without an actor
Actor
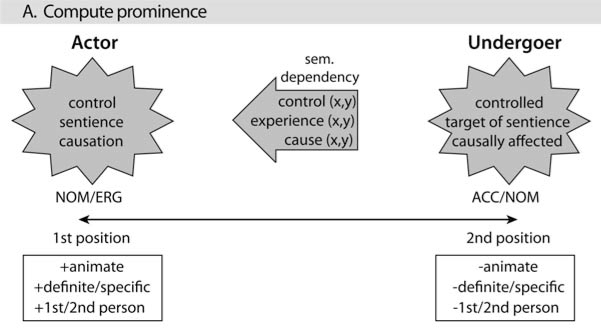
Prominence features
- typical prominence features on non-predicating (“noun-y”) elements:
- animacy
- definiteness
- case
- number
- person
- position
- further prominence features from context:
- agreement
- reference
- etc etc
Typological Distribution
- always there (linear position, animacy, number?)
- always available, but not always expressed (definiteness)
- only available in some languages (morphological case)
Note: three broad categories for non-predicating elements
An actor should be
- the most prominent argument
- as prototypical as possible
Note: 1. local and global maxima; relative and absolute optimality 2. reduction of local ambiguities
Prototypicality matters more than ambiguity!
(Quanatitative)
Model Development
(What I get paid to do)
Purpose
- make more precise, quantitative predictions
- discover underspecification in model
- implement a framework for testing new ideas, refinements, etc.
- explore areas not possible with human testing
- discover unexpected interactions and simplicitiy?
Moonlightig Oracles
- we assume that the identification and extraction of prominence features is a solved problem
- of course it isn’t
- even NP \(\rightarrow\) Det (Adj) NP is beyond us
- Complex stimuli – the reason I cry myself to sleep
Note: 1. “parsing” in a grammatical sense – even at the level of basic phrasal chunking – is very poorly understood and largely ignored in neuro-/psycholinguistics 2. noisy tools, so we try to reduce the input noise as much as possible 3. the other half of my dissertation deals with the statistical methods for using fully natural language
Health Warning
This is my interpretation of the eADM framework. YMMV.
I do not claim to represent Ina’s opinion.
Prominence
A geometrical interpretation
Distance and Distortion in Space
- individual prominence (“magnitude”)
- language specific weighting (“distortion”)
- relative prominence (“distance”)
the metaphor is a tad mixed, I’m still working on making the pieces fit together coherently
Attraction in Space

Prominence Features
- signed value for features – directionality (attraction vs repulsion) matters
- currently “signed binary” / tertiary
- \(-1\): incompatible with actorhod (e.g. accusative)
- \(0\): neutral with respect to actorhood
- \(1\): prototypical for actorhood
Note: 1. \([-1,1]\): relationship to correlation coefficient? 2. inversely proportional to markedness in many languages
Individual Prominence
- reflects how “attractive” an argument is in its own right
- total unweighted prominence for a feature vector \(\vec{x}\):
- $ _i x_i$, or, equivalently,
- \(\vec{x}\dot{}\vec{1}\), where \(\vec{1}\) is the identity vector \((1,1,1,\ldots,1)\)
- $ _i x_i$, or, equivalently,
- “magnitude” is a signed (net) value!
Distortion of Space
- crosslinguistic variation results from different weightings of prominence features
- weights emphasize or reduce (importance of) differences in a particular feature
- topologically invariant: can be thought of the composition of dimensionwise smooth (linear!) transformations
Weighted Individual Prominence
- Non unit scaling: \(\vec{x}\dot{}\vec{1} \Rightarrow \vec{x}\dot{}\vec{w}\)
- \(\vec{w} = c\vec{NP}_\text{prototypical actor}\)
- Euclidean inner product: \(\vec{x}\dot{}\vec{y} = \|\vec{x}\|\|\vec{y}\| cos \theta\)
- WIP as a measure of prototypicality?
- how do we norm this appropriately?
Note: 1. Individual prominence \(\vec{x}\dot{}\vec{1}\) can easily be adjusted to give a weighted magnitude by replacing \(\vec{1}\) with \(\vec{w}\) (fully equivalent to successive dimensionwise distortation followed by magntitude calculation) 2. weights vector equivalent to feature vector of prototypical actor (up to a constant)
Relative Prominence
- different notions of “distance”:
- Manhattan metric
dist: feature overlap - signed “distance”
signdist: $ _i NP2_i - NP1_i $: overall improvement in individual features without weighting - scalar difference
sdiff: difference in signed “magnitudes” $ NP2 - NP1 $
- Manhattan metric
Relative Prominence
signdistis equal tosdiffwhen \(\vec{w} == \vec{1}\)- signedness encodes (fulfillment of) expectations
- \(NP1 > NP2 \rightarrow NP2 - NP1 < 0\) (early actor) preferred
- expected prominence dependency relationship? Note: downhill flow – negative incline
Humor me
Which one do you think provides the best fit to experimental data?
Geometrical Intepretation of “Distance” Function



Greedy to a fault
Source ####how hard is it to get the ball rolling? Note: greediness is towards root: towards downhill: initial accusative prevents assigning -dep to intial argument, but fails to make assigning -dep to later argument easier: prominence as a river, actorhood as a (basin) lake; 0-0 win is less satisfying than a 3-1 win
Strange attractors
- garden pathing
- blindness to well-formed ambiguity
- preference for path which is overall more aligned with prototype, even multiple possible paths exist
- optimal paths through a sentence:
- particularly easy to understand
- stable interpretation, even against contextual and world knowledge
Strange attractors: examples
- Die Gabel leckte die Kuh.
- (Den) Peter hat (die) Maria geschlagen.
Semantic Dependency
This is the wildly speculative part.
Semantic Dependency
This is the wildly speculative part.
- actor category is the root dependency
- assumption of a causal universe
- morphosyntactic syntactic expression tied to verb
- (antisymmetricity of syntactic and semantic dependency)
- undergoer is a pseudo-category dependent upon actor
Parameter Estimations
back in Marburg
- Explicit experimental manipulation of different parameters, measure biosignal
- really hard to do a fully factorial design for even a small subset of features
- strong correlation of features in most languages
- confounds with other known effects
- e.g. animate nouns tend to be more common, first person pronouns are often in prefield
Parameter Estimation
Hopefully a by-product of my experiments here
- Extract weights from data-driven models
- right now: syntactic dependency parsing with eADM’s features
- later: models with new types of dependency relations? Note: rootedness, eager evaluation, position both a marker in its own right and tied to greediness
Questions?